Ⅷ. SQL 응용 - 응용 SQL 작성.
1. 집계성 SQL 작성
1.1. 데이터 분석 함수의 개념
- 총합, 평균등의 데이터 분석을 위해서 복수행 기준의 데이터를 모아 처리하는 것을 목적으로 하는 다중 행 함수.
- 다중 행 함수의 공통 특성.
- 단일행을 기반으로 산출하지 않고 복수행을 그룹별로 모아 그룹당 단일 계산 결과를 반환.
- GROUP BY 구문을 활용하여 복수 행을 그룹핑.
- SELECT, HAVING, ORDER BY 등의 구문에 활용.
1.2. 데이터 분석 함수의 종류
- 집계 함수 : 여러 행 또는 테이블 전체 행으로부터 하나의 결과값을 반환하는 함수.
- 그룹 함수 : 소그룹 간의 소계 및 중계 등의 중간 합계 분석 데이터를 산출하는 함수.
- 윈도 함수 : 데이터베이스를 사용한 온라인 분석 처리 용도로 사용하기 위해서 표준 SQL에 추가된 기능.
1.3. 집계 함수 (Aggregate Function)
1.3.1. 집계 함수의 개념
- 여러 행 또는 테이블 전체 행으로부터 하나의 결과값을 반환하는 함수.
1.3.2. 집계 함수 구문
SELECT 컬럼1 컬럼2 컬럼3 ... 집계함수 FROM 테이블명 [WHERE 조건] GROUP BY 컬럼1 컬럼2 컬럼3 ... [HAVING 조건식 (집계함수 포함)]
- GROUP BY 구문
- SQL 에서 WHERE 구문을 활용하여 조건 대상 ROW를 선택.
- 복수 ROW대상의 데이터 분석시 그룹핑 대상이 되는 부분을 선별시 GROUP BY 사용.
- GROUP BY 구문은 실제 구체적 데이터 분석값을 보고자 하는 컬럼 단위를 선정할 때 사용되는 기준.
- GROUP BY 특성
- NULL값을 가지는 ROW는 제외한 후 산출
- SELECT에서 사용하는 것과 같은 ALIAS 사용이 불가
- WHERE 구문 안에 포함되지 않음
- WHERE 구문은 GROUP BY 보다 먼저 실행되고, 대상이 되는 단일 행을 사전에 선별하는 역할을 함.
- HAVING 구문
- WHERE내 사용 할 수 없는 집계함수 구문에 조건을 적용하는데 사용.
- 일반적으로 GROUP BY 뒤에 기재, GROUP BY 구문의 기준항목이나 소그룹 집계 함수를 활용한 조건 적용시 사용.
1.3.3. 집계 함수의 종류
- COUNT : 복수행의 줄 수
- SUM : 복수 행의 해당 컬럼 간의 힙계
- AVG : 복수 행의 해당 컬럼 간의 평균
- MAX : 복수 행의 해당 컬럼 중 최댓값
- MIN : 복수 행의 해당 컬럼 중 최솟값
- STDDEV : 복수 행의 해당 컬럼 간의 표준편차
- VARIAN : 복수 행의 해당 컬럼 간의 분산
1.3.4. 집계 함수 활용 예시
# 국어 점수가 80점 이상인 학생들의 수 SELECT COUNT(*) FROM STUDENT WHERE 국어 >= 80 # 국어 점수의 합, 영어 점수의 평균값 SELECT SUM(국어), AVG(영어) FROM STUDENT # 국어 최고점, 최저점 SELECT MAX(국어), MIN(국어) FROM STUDENT # 국어 표준편차, 분산 SELECT STDDEV(국어), VARIAN(국어) FROM STUDENT
1.4. 그룹 함수 (Group Function)
1.4.1. 그룹 함수의 개념
- 테이블 전체 행을 하나이상의 컬럼을 기준으로 컬럼 값에 따라 그룹화하여 그룹별 결과를 출력하는 함수.
1.4.2. 그룹함수의 유형
- ROLLUP 함수
- ROLLUP에 의해 지정된 컬럼은 소계등 중간 집계 값을 산출하기 위한 그룹 함수.
- 지정 컬럼의 수보다 하나 더 큰 레벨만큼의 중간 집계 값이 생성.
- ROLLUP의 지정 컬럼은 계층별로 구성되기때문에 순서가 바뀌면 수행 결과가 바뀜에 주의.
- ROLLUP 함수 구문
SELECT 컬럼1 컬럼2 컬럼3 ... 그룹함수 FROM 테이블명 [WHERE ...] GROUP BY [컬럼 ...] ROLLUP (컬럼) [HAVING ...] [ORDER BY ...]- 소계 집계 대상이 되는 컬럼을 ROLLUP뒤에 기재 소계집계 대상이 아닌 경우 GROUP BY 뒤에 기재.
- SELECT 뒤에 포함되는 컬럼이 GROUP BY 또는 ROLLUP 뒤에 기재 되어야함을 숙지.
- ORDER BY 구문을 활용해 계층내 정렬 사용 가능.
- ROLLUP 예시
SELECT DEPT, JOB, SUM(SALARY) FROM DEPT_SALARY GROUP BY ROLLUP (DEPT, JOB)- CUBE 함수
- CUBE는 결합 가능한 모든 값에 대해 다차원 집계를 생성하는 그룹함수이다.
- 세분화된 소계가 구해짐.
- 연산이 많아 시스템에 부담을 준다.
- CUBE 함수 구문
SELECT 컬럼1, ... 그룹함수 FROM 테이블명 [WHERE ...] GROUP BY [컬럼1, ...] CUBE (컬럼1, ...) [HAVING ...] [ORDER BY ...]- CUBE 예시
SELECT DEPT, JOB, SUM(SALARY) FROM DEPT_SALARY GROUP BY CUBE(DEPT, JOPB)- GROUPING SETS 함수
- 집계대상 컬럼들에 대한 개별 집계를 구할 수 있으며, CUBE와 같이 컬럼간 순서와 무관한 결과를 얻을 수 있는 그룹함수이다.
- GROUPING SETS 를 이용해 다양한 소계 집합을 만들 수 있다.
- ORDER BY를 사용하여 집계 대상 그룹과의 표시 순서를 조정하여 보여 줄 수 있다.
- GROUPING SETS 함수 구문
SELECT 컬럼1, ... 그룹함수 FROM 테이블명 [WHERE ...] GROUP BY [컬럼1, ...] GROUPING SETS (컬럼1, ...) [HAVING ...] [ORDER BY ...]- GROUPING SETS 예시
SELECT DEPT, JOB, SUM(SALARY) FROM DEPT_SALARY GROUP BY GROUPING SETS(DEPT, JOPB)
1.5. 윈도 함수
1.5.1. 윈도 함수의 개념
- 데이터 베이스를 사용한 온라인 분석 처리 용도로 사용하기 위해 표준 SQL에 추가된 함수.
- 윈도함수를 OLAP함수 라고도 한다.
✱ OLAP(OnLine Analytical Processing) : 의사결정 지원 시스템으로, 사용자가 동일한 데이터를 여러 기준을 이용하는 다양한 방식으로 바라보면서 다차원 데이터 분석을 할 수 있도록 도와주는 기술.1.5.2. 윈도 함수의 구문
SELECT 함수명 (파라미터) OVER ([PARTITION BY 컬럼1, ...]) [ORDER BY 컬럼A, ...] FROM 테이블명 # PARTITION BY : 선택항목이며 순위를 정할 대상 범위의 컬럼을 설정 # PARTITION BY구에는 GROUP BY구가 가진 집약 기능이 없으며 이로인해 레코드가 줄어들지 않음. # PARTITION BY를 통해 구분된 레코드 집합을 윈도라 함 # ORDER BY 뒤에는 SORT 컬럼을 입력어(떤 열을 어떤 순서로 순위를 정할지 지정)1.5.3. 윈도 함수의 분류 ( Tip. 순행비 )
- 순위함수
- 행순서함수
- 그룹내 비율함수
- 순위함수
- 레코드의 순위를 계산하는 함수
- RANK, DENSE_RANK, ROW_NUMBER 함수가 존재
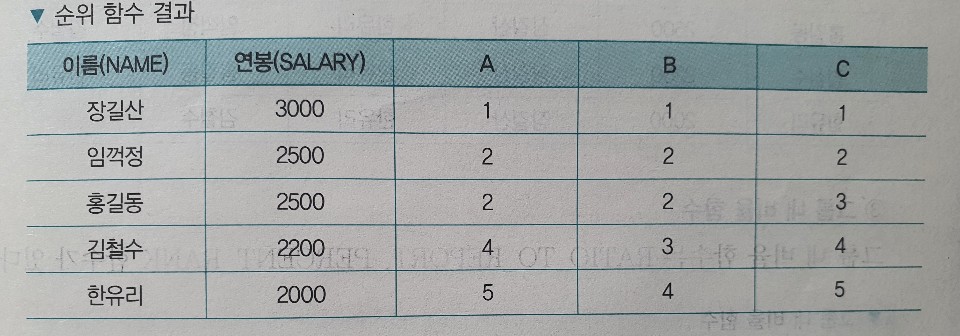
# RANK > 특정항목(컬럼)에 대한 순위를 구하는 함수 > 동일순위의 레코드 존재시 후순위는 넘어감 > 2위가 3개인 레코드인 경우 : 2위,2위,2위, 5위,6위,... # DENSE_RANK > 레코드의 순위를 계산 > 동일순위의 레코드 존재시에도 후순위를 넘어가지 않음 > 2위가 3개인 레코드인 경우 : 2위,2위,2위,3위,4위,... # ROW_NUMBER > 레코드의 순위를 계산 > 동일 순위의 값이 존재해도 이와 무관하게 연속 번호를 부여 > 2위가 3개인 레코드인 경우 : 2위,3위,4위,5위,6위,... # 순위 함수 예제 SELECT NAME ,SALARY ,RANK() OVER (ORDER BY SALARY DESC) A ,DENSE_RANK() OVER (ORDER BY SALARY DESC) B ,ROW_NUMBER() OVER (ORDER BY SALARY DESC) C FROM EMPLOYEE;
- 행순서함수
- 레코드에서 가장 먼저 나오거나 가장 뒤에 나오는 값, 이전/이후의 값들을 출력하는 함수
- FIRST_VALUE, LAST_VALUE, LAG, LEAD 함수가 존재
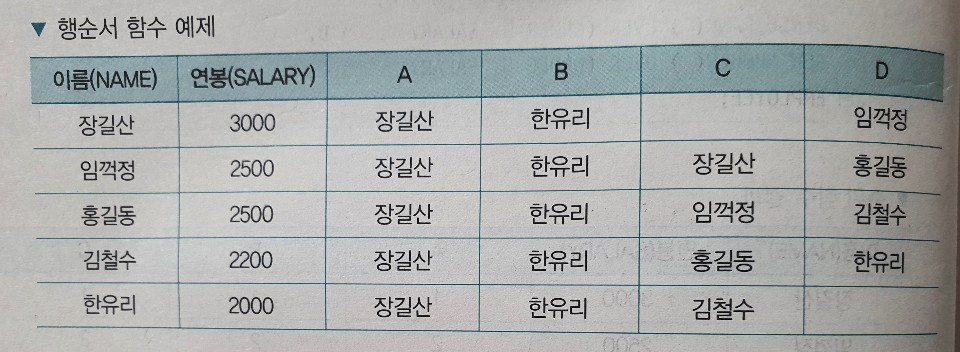
# FIRST_VALUE > 파티션별 윈도우에서 가장 먼저 나오는 값을 찾음 > 집계 함수의 MIN과 동일한 결과를 출력 # LAST_VALUE > 파티션별 윈도우에서 가장 늦게 나오는 값을 찾음 > 집계 함수의 MAX와 동일한 결과를 출력 # LAG > 파티션별 윈도우에서 이전 로우의 값 반환 # LEAD > 파티션별 윈도우에서 이후 로우의 값 반환 > # 행순서 함수 예제 SELECT NAME ,SALARY ,FIRST_VALUE(NAME) OVER (ORDER BY SALARY DESC) A ,LAST_VALUE(NAME) OVER (ORDER BY SALARY DESC) B ,LAG(NAME) OVER (ORDER BY SALARY DESC) C ,LEAD(NAME) OVER (ORDER BY SALARY DESC) D FROM EMPLOYEE;
- 그룹내 비율 함수
- 백분율을 보여주거나 행의 순서별 백분율 등 비율과 관련된 통계를 보여주는 함수
- RATIO_TO_REPORT, PERCENT_RANK 함수가 존재
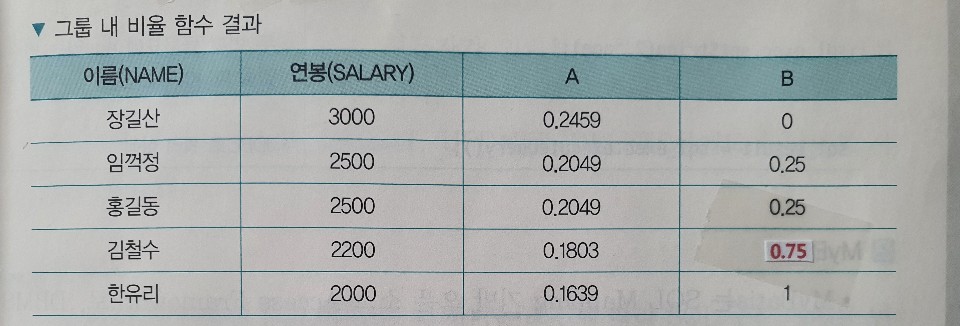
# RATIO_TO_REPORT > 주어진 그룹에 대해 합을 기준으로 각 로우의 상대적 비율을 반환하는 함수 > 결과값은 0~1의 범위 값을 가짐 # PERCENT_RANK > 주어진 그룹에 대해 제일 먼저 나오는 것을 0으로, 제일 늦게 나오는 것을 1로 하여, 값이 아닌 행 순서별 백분위를 구하는 함수 > 결과값은 0~1의 범위 값을 가짐 # 그룹내 비율 함수 예제 SELECT NAME ,SALARY ,RATIO_TO_REPORT(SALARY) OVER (ORDER BY SALARY DESC) A ,PERCENT_RANK() OVER (ORDER BY SALARY DESC) B FROM EMPLOYEE;
2. 특정 기능 수행 SQL문 작성
2.1. 응용 시스템 DBMS 접속 기술
- 자바 데이터베이스 연결 (JDBC; Java DataBase Connectivity)
- JDBC 는 SQL을 사용하여 DBMS에 질의하고 데이터를 조작하는 API를 제공 한다
- MyBatis
- SQL Mapping 기반 오픈 소스 Access Framework로 , DBMS에 질의하기 위한 SQL쿼리를 별도의 XML파일로 분리하고 Mapping을 통해 SQL을 실행.
- MyBatis 는 DBMS 의존도가 높고 SQL 질의 언어를 사용하기 때문에 SQL 친화적인 국내 실무 개발 환경에 맞아서 많이 사용 된다.
- 장단점
- 복잡한 JDBC 코드를 단순화 할 수 있다.
- SQL을 거의 그대로 사용 가능하다.
- Spring 기반 프레임워크와 통합 기능을 제공한다.
- 우수한 성능을 보여 준다.
2.2. MyBatis 작성 문법
2.2.1. SQL 문장의 입력 파라미터 사용 방법
# 사용자명(user_nm)과 생년월일(user_birth_day)을 입력받아 USER_ID를 표시하는 SQL예제 <mappper> <select id="findId" resultType="map"> SELECT USER_ID FROM USER_INFO WHERE USER_NM = #{user_nm} AND BIRTH_DAY = #{user_birth_day} </mappper>
- 응용시스템 UI를 통해서 입력 파라미터를 입력받고 이를 SQL문에 적용한 후 실행
- SQL 문은 미리 작성해 놓고, 사용자가 입력하는 항목에 따라 다른 조건의 SQL을 싱행하는게 목적
- SELECT 문 뿐만아니라 INSERT, UPDATE, DELETE 문등에서 동일하게 사용 가능
2.2.2. 동적 SQL
- 동적SQL : MyBatis 는 조건에 따라 SQL 구문 자체를 변경 할 수 있음
# if 구문을 사용하여 user_birthday 가 있을때만 "AND BIRTH_DAY=" 조건을 실행 예제 <mappper> <select id="findId" resultType="map"> SELECT USER_ID FROM USER_INFO WHERE USER_NM = #{user_nm} <if input_para="user_birth_day != null"> AND BIRTH_DAY = #{user_birth_day} </if> <if input_para="user_main != null"> AND EMAIL = #{user_main} </if> </mappper>
- <if> 외에도 다중 문자열 반복입력시 사용하는 <foreach>, <choose when otherwise> 등이 사용.
2.2.3. 절차형 SQL 호출
- MyBatis에서 절차형 SQL인 사용자 정의함수, 트리거, 프로시저의 실행이 가능
- 사용자 정의함수는 DQL이나 DML에 포함하여 사용되기때문에 별도 호출이 의미가 없으며, 트리거 역시 DBMS에서 바로 실행되므로 별도 호출 불필요
- 주로 프로시저 호출 사용
# 프로시저 호출 예제 <mappper> <select id="execSalesDailyBatch" resultType="map" statementType="CALLLABLE"> { CALL RUN_SALES_AMT_BATCH( #{TARGET_DATE} )} </mappper>
3. 데이터 제어어 명령문 작성
3.1. 데이터 제어어(DCL; Data Control Language)의 개념
- 데이터 베이스 관리자가 데이터 보안, 무결성유지, 병행제어, 회복을 위해 관리자(DBA)가 사용하는 제어용 언어.
3.2. 데이터 제어어(DCL)의 유형
- GRANT : 사용 권한 부여 : 관리자(DBA)가 사용자에게 데이터베이스에 대한 권한을 부여하는 명령어.
- REVOKE : 사용 권한 취소 : 관리자(DBA)가 사용자에게 부여했던 권한을 회수하기 위한 명령어.
3.3. 데이터 제어어(DCL) 명령문
- GRANT(권한부여) 명령문 ( Tip. 그온투위 )
- GRANT 권한 ON 테이블 TO 사용자 [WITH 권한 옵션];
- 관리자가 사용자에게 테이블에 대한 권한을 부여
- WITH GRANT OPTION : 사용자가 권한을 받고난 후 다른 사람들과 권한을 나눠가질 수 있는 옵션
# 예문 (관리자가 사용자 장길산에게 학생 테이블에 대해 UPDATE권한과 그 권한을 필요시 다른 사용자에게 부여할 수 있는 권한 부여) GRANT UPDATE ON 학생 TO 장길산 WITH GRANT OPTION;- REVOKE(권한취소) 명령문 ( Tip. 리온프캐 )
- REVOKE 권한 ON 테이블 FROM 사용자 [CASCADE CONSTRAINTS];
- 관리자가 사용자에게 부여했던 테이블에 대한 권한을 회수
- CASCADE CONSTRAINTS : 연쇄적인 권한을 해제할 때 입력(WITH GRANT OPTION으로 부여된 사용자들의 권한까지 취소)
# 예문 (관리자가 사용자 장길산에게 학생 테이블에 대해 UPDATE 할 수 있는 권한을 회수) REVOKE UPDATE ON 학생 FROM 장길산 CASCADE CONSTRAINTS;
- 정보처리기사 필기 합격 후 실기대비 정리 및 책없이 간단히 보기위해 작성하였습니다.
- 2020년 수제비 정보처리기사 책 기반으로 정리 하였습니다.
- 저작권 관련 문제가 있다면 hojunbbaek@gmail.com 으로 메일 주시면 바로 삭제 조치 하도록 하겠습니다.
[정보처리기사 실기] Ⅷ. SQL 응용 - 응용 SQL 작성. (feat.수제비)